Figure 10-1. A form rendered by the browser.
It is a common myth that JavaScript and accessibility don't go well together. This bad reputation is largely due to the very obtrusive manner in which JavaScript is generally applied, and not the fault of the language. JavaScript is a tool— a means to achieve a goal. If you use a knife as a tool, you could slice bread with it or cause bodily harm. It is not the knife that determines how it is used.
Accessible JavaScript is a misnomer, as we cannot expect all user agents to support JavaScript— from a usability perspective, not from a guideline point of view. Modern user agents are expected to support scripting, and the upcoming Web Content Accessibility Guidelines (WCAG) 2.0 will have a concept of baseline technologies that include scripting. However, designing with accessibility in mind means that we don't assume that visitors have scripting enabled. They might be stuck with old technology that does not support scripting and have no way to upgrade. Or it might be their company's policy not to allow any scripting for security reasons. This means that we don't rely on JavaScript, but instead use it to enhance the experience when and if JavaScript is enabled. The common term for this is unobtrusive JavaScript— JavaScript that helps instead of blocking the way of visitors.
We are currently at a crossroad in JavaScript design. As a web developer, you should be aware that there is a constant change in best practices and ideas in web development. Something that makes perfect sense now might be outdated in a week's time. At the end of the chapter, you will find a list of online resources you can check frequently to keep up-to-date with what's hot and what's not. In this chapter, I will concentrate on some examples of how to approach accessibility when developing JavaScript and what outdated practices and pitfalls to avoid. But first, let's take a look at the big picture.
JavaScript has been around for quite a while. It was not really an issue or even obvious to web users until Dynamic HTML (DHTML) was born. DHTML never was a World Wide Web Consortium (W3C) standard, or even a stand-alone technology. It was a buzzword— marketing speak— for HTML, Cascading Style Sheets (CSS), and JavaScript interacting to make web pages more dynamic. While that sounds like a really good idea, the implementation of DHTML was not necessarily there to help guide web users, but more often than not, driven by excitement for what new browsers could do.
The drivers of DHTML were overly enthusiastic developers and marketing people. It was used to "wow" visitors and reinvent navigation and basic usability concepts in a more complex and, in most cases, less accessible way (similar to the type of use that gave Flash a bad reputation). The wow effect of DHTML got more people interested in JavaScript, but as fast as it got into the limelight, it also lost its zing. It is cool to see parts of the page move, unfold, and zoom the first time you visit it. When the same movement makes you wait the next time you load the web page, it becomes an annoyance rather than a cool feature.
JavaScript gave pages more life; the times of boring linked text documents were over. However, as accessibility was not obvious as a legal requirement and far down on the "to care" list of web designers, no one bothered to test for it before applying the code. Visitors without JavaScript were treated as lower-class citizens, or even left out— no shirt, no tie, no navigation.
The very impractical upshot of sites with JavaScript navigation was that they also blocked out
search engines. This meant fewer visitors. When the dot-com boom was over and
the money ran out, many business stakeholders started cleaning up the sites
rigorously. JavaScript got dismissed as something tried and failed. It had to
go, along with the 600KB Flash intro, the animations, and the cool and groovy
text that was great marketing but didn't tell users
much (for example, "LOOT!
" instead of "your shopping basket
").
What we need now is successful sites. We want to create sites that draw
customers, satisfy their needs, and keep them coming back for more—
thus keeping
a stream of revenue flowing instead of venture capital vanishing.
Our new money-driven design made business stakeholders reconsider another aspect of JavaScript: It can be used to give a visitor immediate feedback— for example, when a form field is filled out the wrong way— without the need for a page reload. This saves the site visitor time and saves the site maintainer server traffic, and traffic costs money. Therefore, JavaScript is still lingering around in the development cycle as something that can help save money and make some things easier for the user.
However, the need to create clean, maintainable, and unobtrusive JavaScript is not very obvious. Web development costs money, so why not just use what is already out there? Why bother reinventing the wheel?
One reason for JavaScript of the obtrusive kind is money. Advertisements only make sense when visitors see and click them. Advertisers will not give you money unless you can show them a lot of hits and leads in return. Therefore, it can happen that marketing dictates using JavaScript to push ads in the visitor's direction via pop-ups, interstitials, and overlays. The mere existence of hundreds of ad-blocking and pop-up blocking software should indicate that this is not what visitors want or see as something worthy of clicking. But, in the end, the business dictates what will be on the site, and the money earned also includes your wage. Luckily though, this is changing. Newer browsers have out-of-the-box pop-up blocking technology, and the legal requirement for accessibility makes unobtrusive JavaScript a bit more interesting again. The old scripts don't work any longer and need replacement. We now have the chance to replace outdated and obtrusive scripts with modern ones.
JavaScript has a bad reputation because it has been used in a very obtrusive manner. When you surf the Web, you will encounter a lot of annoyances only possible with JavaScript, such as unwanted pop-up windows, scripts that turn off your context menus (no right-click menu), pages that don't work without JavaScript, and browser-sniffing scripts telling you that your browser is outdated and that you should upgrade to Microsoft Internet Explorer 6— even if your browser was developed a year after Internet Explorer 6.
All of these give the impression that scripting is used against visitors, rather than as a tool to enhance their experience. Subsequently, this leads to accessibility guidelines and company standards that discard JavaScript as "bad" before even considering its merits.
Another reason for prejudice against JavaScript is the sorry state of some of the code available on the Web. JavaScript has one big advantage over other technologies like Java, C#, PHP, and Perl: It is very easy to learn, and you don't need to install any major development environment to start writing it. A text editor and a browser are all you need, and those come free with every operating system. This is also its biggest disadvantage. Higher programming languages that need assembling before execution, rather than relying on a browser, come with proper debuggers, a much stricter syntax, and test tools. JavaScript lives in the wild, and good JavaScript debugging tools have been available only in the past few years. Add very forgiving browsers and software vendors who claim you don't need to understand scripts (just use the prebuilt ones that come with the editor), and you have a recipe for disaster.
If you were to believe the software promotional material, there is no need to learn anything about web development: Handy, what you see is what you get (WYSIWYG) editors promise interactive websites at the click of a button. No need to fulfill the hard, confusing, and tiring task of learning the tools of the trade. It is true that these tools are getting better every year, and they can perform annoying repetitive tasks for you, but that is where their usefulness ends. They cannot optimize your product for you or make it work in an environment as diverse as the Web. You can paint a picture with a paint-by-numbers kit, but you will have trouble explaining how the harmonies of the picture were achieved and if there is a special meaning in the use of a certain color.
Back when the Web was still relatively young, the ease of developing JavaScript, its subsequent boom, and the fact that the letters DHTML on your resume made the interviewer's eyes shine brightly led to another problem: A mass of ready-made scripts on the Web in so-called script archives, DHTML catalogs, or even cross-browser libraries. These were developed in a time when browsers just started to properly support CSS and the Document Object Model (DOM), and in a lot of cases, "cross-browser" meant that the scripts worked for both Netscape 4.x and Internet Explorer 5, and not according to any standard.
If you plan on using ready-made scripts, make sure to check their date. See if they were updated at all in the last few years when browsers turned from marketing machines to something you can use to surf the Web and optimize to your needs. Later in this chapter, I'll list outdated techniques to test scripts against. If a script uses many of those techniques, don't touch it. Much like a car you get really cheap from a junkyard, it might work nicely, but it will pollute the environment unnecessarily and cost you a bundle in repair costs.
JavaScript was never bad for your visitors; however, bad implementation was— and still is— bad for your visitors. Let's leave browser security holes and their misuse by malicious scripts and cross-server-scripting (XSS) aside, and concentrate on how we still use JavaScript to deter visitors rather than invite and help them. Here are some of the main JavaScript evils users suffer on the Web:
A lot of these are based on an archaic view of websites as a medium and scripting as a technology. We assumed in the past that the website is ours and we define how it looks. We thought that the visitors have the same likes and dislikes we have and want content in the same format that we do. And we assumed that visitors don't know what they want and need us to guide them.
The Web has been around for quite a while now, and our visitors have gotten more versed in its ways and how to use their browsers. Browsers have become better and now allow users to customize them to their needs. Our visitors have also become a lot more diverse. The times of the Web consisting basically of technology-crazy geeks and kids are over. The web population has aged, and visitors with disabilities are not uncommon.
Of course, your audience also varies with the type of web product. You will get fewer pensioners on a fan portal for the latest game console craze than on a council site. However, let's not forget that not only those who use a product are the ones who buy it.
Now that even business stakeholders (probably with a possible lawsuit in mind) start thinking about accessibility and see the benefits of usable websites rather than force-feeding visitors the brand and offers, you should always keep some ideas in the back of your mind:
Remember that the browser configuration and window dimensions are set for a reason: to make it as easy and comfortable as possible for the user to surf with this browser. If you override some of the functionality or change the window size to dimensions your design needs, you might make it impossible for the user to interact with your page. Avoid spawning new browser windows. You cannot expect users to be able to deal with several windows or their setup to allow for them. If your solution really needs to spawn a new window, tell the users about it, so they can make amendments and be prepared for it. Don't hijack the status bar. The status bar gives information about linked documents and other information about the document. It shows a status of how things are, not what you would like them to be.
The first question you should consider before you start any web development is what the visitors need. It is tempting to create a web product to your likings and needs, but in the end, you won't be the one using it or, even worse, you might end up being the only person using it.
Tutorials explaining that accessibility does not interfere with design are deluded; the design has to cater as much to the needs of the visitors as the technology does. The only way you will be able to deliver usable and accessible sites is by getting to know your audience and thinking about their needs first, and then what you want to give them.
In the case of disabled users, this means you need to anticipate what they might use to surf the Web and how it impacts your design. The following list is a start; however, some people have more than one disability or different varieties.
In older accessibility tutorials, you might have read that a text browser with JavaScript turned off is a good simulation of how blind users experience the Web. This is not fully the case, as most screen readers do support JavaScript and render changes in the DOM— inconsistently between different ones for added confusion. It is pretty easy to set up a testing environment for different browsers; however, testing on different screen readers is not that common.
A screen reader is an output device that provides feedback on users' interaction with their computer, in the same way that a monitor is an output device that helps users interact with their computer. Screen readers read out anything that happens when you interact with the operating system, other applications, in browsers, and eventually in your website. Screen readers are complex tools, and their functionality differs from vendor to vendor. This is a big problem. It is the sequel of the browser wars, when we had to consider different browsers supporting different DOMs to make our applications work. The differences are that the user group affected is not as huge and the software involved is not free in Windows environments. There are free screen readers included in Mac OS X and Solaris 10, and there are free screen readers for Linux.
Accessibility concerns are not limited to meeting the needs of people with disabilities.
Depending on the theme of your web product and the intended audience, the range
of abilities and environments of your visitors can be quite mind-boggling. You
will encounter the high-tech, young visitor on a 1600 × 1200 resolution
monitor and an 8 Mbps broadband connection, who considers the Web his real
home. You might also encounter the grandfather with the thick glasses and the
unsteady hand accessing the Web with a 56 Kbps modem and a very outdated
browser ("It works, so why should I change it?
"). Even the high-tech
visitor might not share your enthusiasm for JavaScript and see every use of it
as a potential security risk.
Does this mean you need to limit yourself to a lowest common denominator and create boring websites? Yes, if you see diversity as a blocker; no, if you see it as a challenge. Diversity can be a good thing; for example, the loudspeaker was invented to help hard-of-hearing people, and we all benefit from its invention today.
The environment in which your JavaScript is executed is totally unknown. You cannot assume anything about the user agent or the hardware on which it runs. Knowing what can go wrong makes planning for it easier. The following issues are just some of those that can make your life harder.
Any of these are less of a problem when you stick to the following guidelines when writing JavaScript.
If you want to ensure that your code will work with future user agents and assistive technology, you need to stick to the W3C standards. Unless there is a really good reason, there is no need to use browser-specific extensions to the web standards.
Modern browsers all support the W3C DOM. To test for this, all you need to do is to determine if the document.getElementById object is available. However, as some browsers (like older versions
of Opera) do support this but fail to implement it, you
also need to check for document.createTextNode. Instead of wrapping your whole script in a condition, it is easier
to check if the W3C DOM is available and not apply any more JavaScript if that
is not the case.
if(!document.getElementById || !document.createTextNode){return;}
// other codeThe return statement exits JavaScript and simply keeps
the page as it is, if the script was called when the page was loaded, or
follows a link or button if the script was executed when the user interacted
with that element.
HTML created via JavaScript won't be available when JavaScript is turned off, effectively rendering the page less usable or even completely unusable. Therefore, don't create HTML that is absolutely necessary, such as the navigation, via JavaScript.
There is a practical side effect of following this rule: Not creating HTML via the DOM makes the product a lot easier to maintain. Non-JavaScript-savvy colleagues won't need to try to deal with something they are not sure about to change the document. This is especially important in distributed development environments or when the client becomes the maintainer.
An accessible site should start with a semantically correct, well-structured HTML document. Using the DOM gives you a lot of control over the document. You can generate any HTML you want— even invalid HTML— and automated validation of the document would still report no issues. However, the final user agent will need to try to render this code, and may choke on it.
We stopped using CSS to make elements look like headers instead of using real header elements. The same applies to the DOM. Redundant HTML elements to fix a design or add a design feat is— well, redundant, no matter what technology was used to add it.
This is also true for server-side
scripting. Just because you can create and maintain inline mouseover and mouseout handlers easily in a loop doesn't make them a good idea. For
starters, they unnecessarily bloat the document.
DOM JavaScript allows you to turn almost any page element into something interactive. The question is
whether the visitors using their user agents can reach the interactive element.
A common mistake is to make elements react only to mouseover events rather than onclick. A visitor dependent on a keyboard will never be able to activate
those. Even if you use onclick handlers on elements, they may not be reachable via keyboard or
voice recognition. When you develop accessible interactive pages, the keyboard
is your friend. Elements that can be reached via tabbing are very likely to be
available to other assistive technologies.
JavaScript allows you to come up with your own keyboard events. If you want to use those, try to make sure that they won't interfere with necessary keyboard shortcuts of the user agent, and make it clear to the visitors what the shortcuts are.
You can do a lot to enhance websites via JavaScript; however, sometimes less is more. It is very tempting to add a lot of scripts with the best of intentions, but in regard to accessibility, it is always a good idea to lean back and reflect: Does this script help visitors to reach a goal faster or overcome a problem, or is it just there because it is flashy or trendy?
A good example is the use of font-resizing tools that depend on JavaScript and cookies. These are seemingly very helpful to visitors suffering from low vision, but simply resizing the font inside the browser is not enough to help them. A person with low vision will need to have the whole operating system in larger fonts or have the whole screen magnified, not only the current web page. A lot of font-sizing widgets simply simulate what browsers do out of the box anyway: Give the user an option to resize the font. Nearly every browser has that feature, some more prominently than others. Even worse, badly implemented resizing widgets expect JavaScript and cookies to be enabled, which is not necessarily a given in the user's computer setup. The browser functionality keeps the font size choice and applies it to all websites. A font- sizing widget would not give that option, and users would be expected to use one of those on every page they visit. In essence, you use a solution that may fail to work around a problem that was solved by user agents already and only became an issue because the initial font size of your page is too small.
Browsers have options for resizing the fonts. In Firefox, press Ctrl++ (plus) and Ctrl+- (hyphen) to increase and decrease the font size, respectively. In Safari, press Apple++ and Apple+-. In Internet Explorer, choose View > Text Size. Internet Explorer 7 has a zoom feature that magnifies the whole document, including images. Opera has had such a zoom feature for a while.
JavaScript can make web pages behave completely differently from how you expect them to behave. This can confuse visitors or make it impossible for them to use your products. You cannot expect visitors to read instructions on how to use your site; a good product is intuitively usable. This might even mean that it should follow conventions that are cumbersome and appear inefficient.
A holy war debate in the web development community centers around whether the browser controls as we know them in HTML are enough. For example, a slider control is more intuitive to nontechnical visitors, as it is a real-life control we use every day. However, on the Web, the slider control is not available out of the box (a scrollbar does not change a value; therefore, it is not a slider) and may not be usable via keyboard or voice control, or indicate the current value to a blind user.
User testing can help. If your users hit the back button repeatedly and thereby lose the state of the application, it might not be as intuitive as you originally thought it was.
One of the biggest causes for buggy code
and websites that don't work is that their developers tried to access methods,
elements, or objects that were not available. While some browsers will allow
you to try to access attributes of a nonexistent element,
others will throw an error and show it to the visitor. For example, the
following works only when the object o is available and will throw an error if it isn't.
function addclass(o,c)
{
o.className+=o.className?' '+c:c;
}Testing for the object before trying to access its attributes is safer. This code will not execute unless the object is available:
function addclass(o,c)
{
if(o)
{
o.className+=o.className?' '+c:c;
}
}A lot of scripts hailing from the times of the DHTML craze use global variables to store information and expect them to be available at all times. This can lead to problems when more than one script is used on the page or some third-party software adds extra scripts to the document. Instead of relying on global variables, you can keep the variables in the scope of the function or even use object attributes.
Another big mistake is to use the style attribute collection of an object to define its visual
representation. The definition of how something should look in a user agent is
the job of CSS. Instead of mixing CSS and JavaScript, you can add and remove
classes from the element in question and keep the maintenance of the look and
feel in the style sheet. This is not always possible—
for example, with
drag-and-drop interfaces that need to constantly change the element coordinates
via the style attributes—
but can help you solve a lot of problems. It also
means that you don't necessarily need to know CSS and can leave its
complexities to the designer.
JavaScript is a wonderful tool to give your websites more life, to make them appear a lot more dynamic, and to prevent visitors from suffering unnecessary page reloads. This might seem redundant in a time where broadband is considered the norm (at least in the Western world), but page reloads are more than just transmission of page data. The page needs to be rendered by the browser on every reload and that can— depending on the speed of the computer, available RAM, or the system load— take much longer than the actual loading of the page.
The main rule of creating unobtrusive
JavaScript, or indeed any accessible web design, is separation of the different
development layers. The structure (defined in the HTML), the presentation
(defined in the CSS), and the behavior (defined in JavaScript) all need to make
sense and be maintainable without impacting the others. There might be
overlaps, like CSS classes needed to achieve a certain effect or HTML elements
with the correct IDs, but good documentation can take care of these issues. An
accessible website needs to be accessible to all, regardless of user agent, operating system, connection speed, display size, and
other factors. Predicting all of these is next to impossible, and the only
things you can do is stick to standards and make sure that you don't rely on
anything that might be unavailable.
Writing proper unobtrusive JavaScript is an ever-changing skill. As a developer, you cannot have all user agents at your disposal, and you cannot possibly emulate every environment in which your code might be viewed. What you can do is make sure your code does not assume any givens and watch for publications on the Web discussing the newest techniques and practices. Sometimes, you need to consider and weigh the consequences: Should I make sure my code is spot-on, totally unobtrusive and bloated, or should I keep it simple and make it achieve what is necessary for this particular problem?
Every so often, some hard-core programmers will come up with the JavaScript library to end all JavaScript libraries. Often, these scripts are based on practices that make sense in Java or Perl but don't apply so well to JavaScript. The difference is that JavaScript is executed on the client side, and this is unknown territory. Therefore, it is sometimes wiser to keep it short and sweet and add some appropriate comment, rather than to use the 140KB JavaScript include file, following regular programming practices. After all, the turnaround and changes in the web design area are a lot quicker than those on the server side.
In this section, we'll look at JavaScript's role in web development, and then some examples of unobtrusive Java coding. Finally, I'll list some outdated scripting methods and their replacements. The code examples in this chapter are available from the friends of ED website, in the code download section.
One of the basic concepts of accessibility-aware web development is to realize that a document on the Web is not what meets the eye on your monitor. Most web pages are not visual constructs; they are basically text. It's true that some websites make sense only when you can see them— like Flickr or Google Maps— but these are web representations of applications. In most cases, you'll want to deliver information that is in text format.
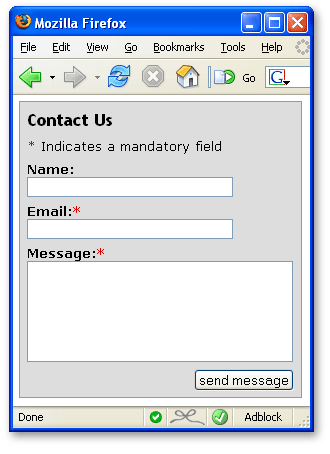
The text features embedded HTML tags that define the document structure and tell the user agent what it contains. CSS defines how the user agent should render these elements. Last but not least, languages like JavaScript can access this text or the HTML elements via the DOM. The DOM offers you the document as a collection of nodes and attributes and allows for programmatic changes to the document structure. For example, the following HTML is rendered in the browser as a form:
<form action="send.php" method="post" id="contactform">
<h1>Contact Us</h1>
<p><span class="required">*</span> Indicates a mandatory field</p>
<p>
<label for="name">Name:</label>
<input type="text" name="name" id="name" size="30" />
</p>
<p>
<label for="email">Email:<span class="required">*</span></label>
<input type="text" name="email" id="email" size="30" />
</p>
<p>
<label for="Message">Message:<span class="required">*</span> </label>
<textarea name="Message" id="Message" cols="30" rows="5"> </textarea>
</p>
<p class="submit">
<input type="submit" name="send" id="send" value="send message" />
</p>
</form>Once executed within a browser, you should see a form like the one shown in Figure 10-1.
Figure 10-1. A form rendered by the browser.
The DOM representation of the same HTML is a collection of nodes, attributes, and values, as you can see in the Mozilla DOM Inspector, shown in Figure 10-2.
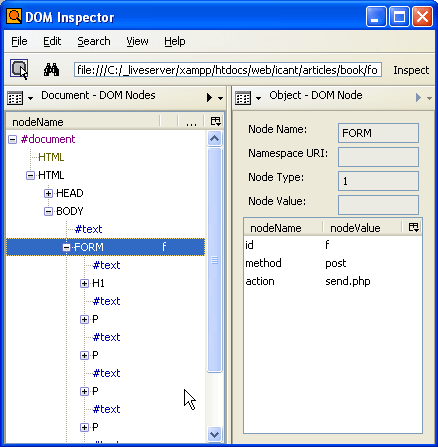
Figure 10-2. Screen shot of the Firefox DOM Inspector, showing the DOM representation of an HTML document.
You can completely change documents via
the DOM and a programming language (which is usually JavaScript, but as the DOM
is language-independent, you can also use it with Java, PHP, and many other
languages). You can access all items in the document,
change them, read their values, rearrange them, delete them, or even create new
ones. For example, if you wanted to change the action of the form when
JavaScript is available, you could use the getElementsByTagName method together with the setAttribute method:
var f=document.getElementsByTagName('form');
if(f.length>0)
{
var ourform=f[0];
ourform.setAttribute('action','otherscript.php');
}In plain English, this would be "Define f as a list of all the form elements in the document. If this list
has entries—
which means there is at least one—
get the first form element
(computers start counting at 0) and set its attribute with the name action to otherscript.php."
As this HTML has a defined ID with the value contactform, you could also use the getElementById method, which saves you defining the variable ourform:
var f=document.getElementById('contactform');
if(f)
{
f.setAttribute('action','otherscript.php');
}Using the DOM allows you to completely change the document, without any need to mix HTML and JavaScript. This technique of separating JavaScript into its own document and harnessing the DOM as a means to change HTML has been lately christened the behavior layer and crops up sooner or later when the talk is about modern web development and scripting. It means that by using the DOM, you turn JavaScript into an own separate and independent layer in the whole web development process and stop treating it as an HTML add-on.
We stopped using font tags and
presentational attributes like align and bgcolor, and defined all these settings using CSS. The defined styles are
then applied to any HTML document that utilizes the CSS file. That way, we
defined the HTML as a structure layer and the
CSS as a presentation layer. We now stop mixing
JavaScript and HTML, and put all JavaScript in a separate file and define yet
another layer—
the behavior layer. JavaScript describes how a document behaves,
the same way as CSS describes how the document is rendered. Figure 10-3
illustrates the three levels of web development.

Figure 10-3. The three levels of web development: HTML - structure, CSS - presentation, Javascript - behaviour.
The question the web development community is arguing over right now is what constitutes
behavior. Is it everything that changes when the user interacts with it? By
that argument, a hover effect that changes a link's color should be implemented
in JavaScript and not in CSS. What about hiding and showing elements? Is that
to be done with CSS or JavaScript? The answer is simple: Whatever fits. Both
are tools, and from an accessibility point of view, neither CSS nor JavaScript
is trustworthy.
The following are some points in favor of JavaScript:
JavaScript and CSS can both access elements of the HTML, as shown in Table 10-1. The support information is based on the majority of current browsers, including Internet Explorer 6. Firefox, Opera, and Safari support more CSS2, and some even support more CSS3 than Internet Explorer 6 does.
| Task | CSS | JavaScript and DOM |
|---|---|---|
| Get all paragraph elements | p
{ } |
document.getElementsByTagName('p'); |
Get the paragraph with
the ID mypara |
#mypara
{ } |
document.getElementById('mypara') |
| Get the third paragraph of the document | document.getElementsByTagName('p')[2] |
|
| Get the next element following the third paragraph | document.getElementsByTagName('p')[2].nextSibling |
|
| Get the element before the third paragraph | document.getElementsByTagName('p')[2].previousSibling |
|
| Get the first element inside the third paragraph | document.getElementsByTagName('p')[2].firstChild |
When it comes to generating content, JavaScript and DOM leave CSS far behind. While CSS2 has the :before and :after pseudo selectors that can add content before and after an element, this content is limited to generating text content, displaying attributes, numbering, adding quotation marks, or embedding media. JavaScript and DOM have a lot more to offer, as shown in Table 10-2.
| Command | Effect |
|---|---|
createElement(element) |
Creates a new element |
createTextNode(string) |
Creates
a new text node with the value string |
setAttribute(attribute,value) |
Adds a new attribute with the value to the element or alters the current attribute |
appendChild(child) |
Adds
the child node as the last child to the element |
cloneNode(bool) |
Makes
a copy of the current node; if bool is true, it includes all child nodes (the clone is simply a copy of
the HTML and does not include any JavaScript functionality you might have
applied to the element beforehand) |
hasChildNodes() |
Returns true if the element already has child nodes |
insertBefore(newchild,oldchild) |
Inserts the node newchild before oldchild |
removeChild(child) |
Removes the child node |
replaceChild(newchild,oldchild) |
Replaces oldchild with newchild |
removeAttribute(attribute) |
Removes the attribute from the element |
Table 10-2. JavaScript and DOM Content Generation
Once you reached an element, either via getElementsByTagName or getElementById, you can
navigate the node tree via other attributes, as listed
in Table 10-3.
| Attribute | Meaning |
|---|---|
childNodes |
An
array of all the childNodes of an element. If you don't know how many
nodes are in another node, you can loop through this array. There are also
shorter notations for the first and the last child: firstChild instead of childNodes[0] and lastChild instead of childNodes[this.childNodes.length-1]. |
parentNode |
The node the current one is contained in. |
nextSibling |
The next node on the same level as the current one. |
previousSibling |
The previous node on the same level as the current one. |
Every node you reach has a range of attributes and methods, as listed in Table 10-4.
| Attribute | Meaning |
|---|---|
attributes |
Array of all the attributes of the node |
data |
Returns or sets the textual data of the node |
nodeName |
Returns the name of the node (in HTML, the element name) |
nodeType |
Returns the type of the node (in HTML, this is 1 for element, 2 for attribute, or 3 for text) |
nodeValue |
Returns or sets the value of the node; this is the text when the node is a text node, the attribute value when it is an attribute node, and null when it is an element |
getAttribute(attribute) |
Retrieves the attribute value |
Event handlers are what make things click, sometimes quite literally. Many event handlers are available, and some of them hint at the chance to create really sexy, rich user interfaces with JavaScript. In terms of accessibility, there is a danger that you can go in a direction that simply cannot be accessible to all.
Event handlers execute a script when the
user agent detects a certain action. For example, the click event handler triggers a function when the visitor clicks an
element (or presses Enter after tabbing to the link), mouseover is executed when the mouse pointer hovers over the element, and mouseout is triggered when the mouse pointer leaves the element.
Accessible websites need to be device independent, and the WCAG demands the use of device-independent event handlers for your scripts:
Otherwise, if you must use device-dependent attributes, provide redundant input mechanisms (i.e., specify two handlers for the same element):
Use "
onmousedown" with "onkeydown"Use "
onmouseup" with "onkeyup"Use "
onclick" with "onkeypress"
Users who depend on keyboard browsing do
normally have a key set up to simulate clicking (either the Enter key or
spacebar), and that key triggers the click event. By using keypress, you might hijack other keyboard functionality the user needs.
Examples are the type-ahead functionality of Mozilla, which automatically jumps
to text or links containing the word you enter, Opera's extensive keyboard
shortcuts (like the A key for next link), or the JAWS keyboard controls. While
it is true that all of these are the issues the browser developers should
tackle, it is your visitors who will suffer the problems they cause. This means
that by following the WCAG, you might create a less
accessible script. In practice, click typically does not need an extra "fallback" event
handler.
So, how should you handle event handlers?
Consider a drag-and-drop interface. This works fine for a visual user with good
mouse skills, but you cannot assume that visitors who depend on voice
recognition or screen readers will be able to use it—
although their assistive
technology does support this event! It doesn't hurt to add a click handler as
well, thereby making everyone happy.
You can add event handlers in several ways, the least appropriate being inline:
<a href="index.html" onmouseover="doJSMagic()"
onclick="doJSMagic();return false" id="home">Home</a>The less obtrusive way is to use a function to add handlers via the DOM Level 1 direct assignment:
function addMagic(){
// check if DOM is available
if(!document.getElementById || !document.createTextNode){return;}
// check if there is a link with the id home
var hl=document.getElementById('home');
if (!hl){return;}
// apply the event handlers calling the function
hl.onmouseover=doJSMagic;
hl.onclick=function()
{
doJSMagic();
return false;
}
}The problem with this approach is that you can add only one handler at a time. If you want to call more than one function, you need to add it inside the anonymous function assignment:
function addMagic(){
// check if DOM is available
if(!document.getElementById || !document.createTextNode){return;}
// check if there is a link with the id home
var hl=document.getElementById('home');
if (!hl){return;}
// apply the event handlers calling the function
hl.onmouseover=doJSMagic;
hl.onclick=function()
{
doJSMagic();
moreSpells();
return false;
}
}This is not really an issue when you use one script, but when you are developing more complex JavaScript applications, you might have different functions trying to assign event handlers to the same object, especially the window.
A clever developer named Scott Andrew came up with a function to dynamically add event handlers to an element. This is a much cleaner way, but the downside is that you need to do a lot of object detection and code forking to make it work in newer browsers and the ones that are getting a bit rusty now, like Internet Explorer 6.
function addEvent(elm, evType, fn, useCapture)
// cross-browser event handling for IE5+, NS6+ and Mozilla/Gecko
// By Scott Andrew
{
if (elm.addEventListener) {
elm.addEventListener(evType, fn, useCapture);
return true;
} else if (elm.attachEvent) {
var r = elm.attachEvent('on' + evType, fn);
return r;
} else {
elm['on' + evType] = fn;
}
}
function addMagic()
{
// check if DOM is available
if(!document.getElementById || !document.createTextNode){return;}
// check if there is a link with the id home
var hl=document.getElementById('home');
if (!hl){return;}
// apply the event handlers calling the function
addEvent(hl,'mouseover',doJSMagic,false);
addEvent(hl,'click',doJSMagic,false);
addEvent(hl,'click',moreSpells,false);
}This demonstrates the power of addEvent. With it, you can easily add several functions to a single event
handler. If the visitor now clicks the element with the ID home, both the functions doJSMagic and moreSpells will be triggered without having to use an anonymous function, as
in the earlier example. Using addEvent also means that your scripts will never be in the way of other
scripts, as you don't hijack the event for your script exclusively. In the case
of an element, that is never that much of a problem. In the case of the window
and its onload handler, it could be fatal for other scripts.
Using addEvent makes it easier to use several different
scripts on a page without having to amend them to work together. However, it
also has its drawbacks. The biggest drawback is browser support. If you need to
support older browsers like Internet Explorer 5 on the Mac or Netscape 4.x on
the PC, you cannot use addEvent exclusively. Another annoying problem is that addEvent does not allow for the object that was activated to be sent to a
script. With onclick, it is easy to
get the object that was activated, using the this keyword. Consider this image example:
<p><img src="robot_tn.gif" alt="Battery powered Toy Robot" /></p>
<p><a href="robot.jpg" onclick="showPic(this.href);return false">
Large Image</a></p>
JavaScript:
function showPic(picurl){
var picwin = window.open(picurl,'picwin',' [… window attributes …]');
return false;
}This will work, as picurl is submitted. If you add showPic via addEvent however, you cannot send the parameter, and you'll need another function to recognize which element has been activated to read out the href attribute. Furthermore, you'll also need a third function to stop the link from being followed, as return false does not stop the execution of the script when it is applied via addEvent.
Event handlers are a very vast and large field when it comes to developing JavaScript and different browsers, plus their lack of support of the W3C standards can prove to be quite a headache. Fortunately, enthusiastic web developers find problems and their solutions almost every week. Access Matters has a JavaScript section that explains the problems of event handlers in detail.
The definition of the look and feel of a document is best kept in a separate CSS file. However,
it is possible in JavaScript to access the style attribute collection of an element directly, and you might encounter older
scripts that do that a lot, making it hard for you to change the look and feel
of the effect they produce. For example, you could simulate a CSS rule completely
in JavaScript, as in the following example.
CSS:
#specialOffer {
border:1px solid #000;
background:#cfc;
color:#060;
font-size:1.3em;
padding:5px;
}JavaScript:
var special=document.getElementById('specialOffer');
if(!special){return;}
special.style.border='1px solid #000';
special.style.background='#cfc';
special.style.color='#060';
special.style.fontSize='1.3em';
special.style.padding='5px';The difference is that you can not only
set the styles in JavaScript, but you can also read them. That way, it is
easily possible to write a function that shows and hides an element by setting
its display property to none when the page loads and read it when another element is
activated. You might have encountered functions like this:
function showhide(o)
{
// check if the object exists
var obj=document.getElementById(o);
if(!obj){return;}
// if the object display setting is 'none',
// set it to 'block' and vice versa
obj.style.display=obj.style.display=='none'?'block':'none';
}There are several problems with this type
of function. First, elements that get a display property of none or visibility of hidden are not read by
some screen readers. Second. if there are more changes to the look and feel of
the hidden and the shown element, you need to add more and more style-changing
lines to the function, or some third-party developer or designer will have to
go through the JavaScript code to change the look and feel, which is neither
safe nor easy on the maintenance time budget.
A better way is to change the className attribute of the element you want to change, thus applying a class
to it that can be maintained by a CSS developer without any scripting
aspirations. A script that turns an unordered list into a dynamic navigation
could allow for different styles by adding a class. You can then create a rule
in your CSS to display the navigation differently when JavaScript is available
and when it is not.
<ul id="nav">
<li><a href="index.php">Home</a></li>
<li><a href="about.php">About Us</a></li>
[… more options …]
<li><a href="portfolio.php">Portfolio</a></li>
<li><a href="contact.php">Contact</a></li>
</ul>
function initmenu()
{
var n=document.getElementById('nav');
if(!n){return;} n.className='dynamic';
[... more code ...]
}When JavaScript is available, the <ul> will get the class dynamic, which allows you or a future maintainer to define different styles
for the plain menu and the one that is enhanced via scripting:
/* plain menu */
ul#nav{
[… settings …]
}
/* scripting enhanced menu */
ul#nav.dynamic{
[… settings …]
}However, if you simply change the className attribute, you might overwrite already existing classes. The class attribute allows for several values, separated by a space. That is
why you need to check if there is already a class applied and add the new one
preceded by a space.
function initmenu()
{
var n=document.getElementById('nav');
if(!n){return;}
n.className=n.className?n.className+' dynamic': 'dynamic';
[... more code ...]
}You run into the same issues when you want to remove classes that have been added dynamically, as
some browsers don't allow for spaces before the first class or after the last
class. This can be pretty annoying, and it is easier to reuse a function that
does this for you:
function cssjs(a,o,c1,c2)
{
switch (a){
case 'swap':
o.className=!cssjs('check',o,c1)?
o.className.replace(c2,c1):o.className.replace(c1,c2);
break;
case 'add':
if(!cssjs('check',o,c1)){o.className+=o.className?' '+c1:c1;}
break;
case 'remove':
var rep=o.className.match(' '+c1)?' '+c1:c1;
o.className=o.className.replace(rep,'');
break;
case 'check':
return new RegExp("(^|\\s)" + c1 + "(\\s|$)").test(o.className)
break;
}
}This function uses four parameters. a is
the action you want it to perform: swap, add, remove, or check. swap replaces one class
name with another, add adds
a new class, remove removes it, and check tests if the class was already applied to the
element. o is the object/element
to which you want to apply the class. c1 and c2 are the two different classes. c2 is necessary only when the action is swap.
If you apply this tool function to the menu example, you get the following:
function initmenu()
{
var n=document.getElementById('nav');
if(!n){return;}
cssjs('add',n,'dynamic');
[... more code ...]
}You will see more examples of this function in the "Element Visibility" section later in this chapter.
Opening links in new browser instances or windows is a big usability and accessibility dilemma. On the one hand, you might need to do so; on the other hand, you cannot assume that the user agent supports several windows. For example, text browsers like Lynx do not support multiple windows.
Unsolicited opening of new windows— so-called pop-up windows— has been a marketing practice ever since browsers supported it, and is not the issue here. Let the plethora or pop-up blocking software out on the market deal with that. Sadly enough, badly developed pop-up blocking software might even interfere with windows that were opened with the user's consent. There is not much we can do about this, except for hoping users will spot that software mistake and tell the vendors about it. Another, maybe even more important, issue is that due to the constant misuse of pop-ups for unsolicited advertising, visitors are likely to see all new windows as a nuisance and close them before even glancing at their content.
An example of a reason to open a new window is to link to extra information on a third-party page or a lengthy terms and conditions page. This makes sense to show in a pop-up window, as you don't force the visitors to leave the document and thereby lose all the data they might have entered in a form already. However, if you have the chance to store this data in a session or database before going to the other document and reinstate it when going back, do so— it is the safest and most accessible way.
The following general rules apply to opening new windows:
Opening the linked document in a new
browser instance is possible in HTML, via the target attribute. The target attribute can be the name of a frame inside the document or the
name of another window. It can also be one of the generic terms blank, top, or parent preceded by an underscore. The _parent and _top values make sense only inside a frameset pointing to one frameset
above the one the document was opened in or the main browser window. The _blank value will open a new browser instance, if the
visitor hasn't disabled this option (some browsers allow you to do that).
The following code opens a new browser
window in an accessible manner using HTML exclusively. The only drawbacks are
that target is a deprecated attribute for modern HTML derivatives and that
users who cannot open new windows will get a confusing message saying that the
link opens in a new window:
<a href="http://www.example.com" target="_blank">
visit our example client (opens in new window)</a>Visitors should be notified that this
link opens in a new window inside the text of the link. A lot of accessibility
tutorials state it is enough to add a title attribute with that information. However, not all assistive
technologies support title attributes, and users tend to turn them off, as titles have been
abused for extraneous text because of their tooltip representation in visual
browsers. The information contained in titles will also be hidden from keyboard
users; with visual user agents, only hovering over the element with the mouse
pointer reveals the title.
Fans of strict XHTML frown upon the target attribute, as the strict derivatives of XHTML and HTML do not allow
it. If you want to use strict markup derivatives, and you still want to have
pop-up windows for visitors with JavaScript enabled, you can use either the rel attribute or CSS classes in conjunction with an appropriate script.
Without JavaScript, the page will open in the same browser window.
<a href="example.html" rel="popup">help</a>
<a href="example.html" class="popup">help</a>The class method has its merits, as it also allows you to style the links
accordingly. The problem is that the styling makes sense only when CSS and scripting is enabled. Therefore, if you go the CSS
classes route, you should apply the extra styling only when JavaScript is
available. The rel method indicates
link relationships, and a pop-up is a link relationship—
one that is made up and
not supported by browsers. You could also use the profile attribute of the head element to make this relationship obvious to
user agents.
JavaScript allows you to open a new window with certain measurements and turn off parts of the browser. The latter is particularly popular with design agencies, as the designer's nightmare— not being able to control the size of the canvas— can be avoided by opening a pop-up window with fixed dimensions.
To open a new window in JavaScript, you use the open method of the window object. This method comes with various window attributes in a
rather uncommon syntax:
newwindow = window.open("document.html",
"windowname","attribute1=value,attribute2=value,attribute3=value");The third parameter is a comma-separated list of attribute and value pairs. The attributes and their meaning are legion. You can find a good list of them, including browser support, on the German site SelfHTML.
One bad practice that is commonly used on the Web is to make a pop-up link dependent on JavaScript:
<a href="javascript:window.open('example.html','','width=400,height=400,
location=no,menubar=no,resizable=no,scrollbars=no')">help</a>Without JavaScript, this help will not be helpful, as nothing happens when the frustrated visitor activates this link. Even worse, if the visitor has JavaScript enabled and gets a pop-up window, the restrictions of the window defined in the attributes might render it useless. A low-vision user who needs to have a large font size might not be able to read the content, as it has been cut off and the user will not be able to reach it because both scrolling and window resizing have been turned off. It is much safer and more user-friendly to keep the browser as it is. You simply cannot predict all the needs of your visitors.
Using an onclick handler on the link also ensures that there is no dependency on JavaScript:
<a href="example.html" onclick="window.open(this.href,'',
'width=400,height=400,resizable=yes,menubar=yes,
scrollbars=yes');return false">help</a>A couple items here might be confusing
and need clarifying. The first mystery might be this.href. The magic word this always refers to the element that is activated. The href attribute is what the link points to. Using this.href saves you a needless repetition of example.html as the document location of the pop-up window. Secondly, the return
false statement at the
end of the onclick command ensures
that the link is not being followed in the main window;
otherwise, example.html would be
opened both in the pop-up window and the main window.
If you want to make sure that a new
browser window will be opened regardless of JavaScript availability, you can
add a target attribute and inform the visitor about it:
<a href="example.html" target="_blank"
onclick="window.open(this.href,'','width=400,height=400,resizable=yes,
menubar=yes,scrollbars=yes');return false">
help (opens in a new window)</a>As explained earlier in the "Interactivity"
section, this example will make automated testing choke and is a violation of
the WCAG 1.0 guidelines, unless you add an onkeypress handler. This handler would do more bad than good, unless it also
tests which keys were pressed and takes appropriate
action. As developing proper keypress-handling scripts in JavaScript can be
tricky, you need to rethink your pop-up windows as a whole if you want the site
to be accessible and pass automated validation.
One thing is for certain: Pop-up windows
need JavaScript to get their full effect. With that in mind, the most logical
solution is to shift all the pop-up functionality to
JavaScript and stick with the plain-vanilla HTML link opening the document in
the same window. For the window-opener links, you can use the rel="next" attribute, and for the closing ones, you can use the rev="prev" attribute. These are normally used for pages inside a collection of
pages, like a book, linking to the next and previous chapters. If you want to
use them as they were intended, you can also come up with your own "poptrigger" and "popup" values.
Let's say that you want a help document to open in a pop-up window. The most basic example— assuming the worst— would be a link to the help in the document that should spawn the pop-up window and a link back to the previous page in the pop-up document.
<a href="help.html" rel="popup">help</a>
<a href="form.html" rev="poptrigger">back to previous page</a>This works in any case. If you were to
use a target attribute, the link back wouldn't be possible, as you cannot close
windows without JavaScript. The help.html document might open in a new window, but open the form in the new
window when the visitors activate the link back to the previous page.
Now, if JavaScript is available, you want the pop-up link to open a new window—
and tell the visitor
about it—
and the back link should close the current window. You could do this
with inline event handlers, inline JavaScript, and noscript:
<!—
on the opener page —
<a href="help.html" onclick="window.open(this.href,'','width=400,height=400,resizable=yes,
menubar=yes,scrollbars=yes');return false"
rel="popup">help</a>
<script type="text/javascript">
document.write('(opens in a new window)');
</script>
<!—
in the pop-up —
<a href="form.html" onclick="window.close();
return false" rev="poptrigger">
<noscript>back to previous page</noscript>
<script type="text/javascript">document.write('close window');</script>
</a>Not a nice sight to behold, a nightmare to maintain, and— depending on the user agent and the HTML version— a source of various failures and validation errors.
Let's develop an unobtrusive script that triggers the same functionality without mixing HTML and JavaScript. The script should do the following:
window.opener object, which indicates that the current document is open in a pop-up window.window.opener object, loop through all the links and test if they have a rev attribute of "poptrigger". If so, replace the link text with the "close window" message and attach a function that will close the window when the link is activated.window.opener object, loop through all the links and test if they have either a target attribute or a rel attribute of "popup". If so, add the "opens in a new window" message and attach a function that will open a window when the link is activated.This translates to the following reusable JavaScript functions:
function popuptools()
{
// test if DOM is available
if(!document.getElementById || !document.createTextNode){return;}
// define variables
// target to indicate popup link
var triggerTarget='_blank';
// rel to indicate popup link
var triggerRel='popup';
// rev to indicate closing link
var backRev='poptrigger';
// message to add to a link with a popup rev but no target
var openMessage=' (opens in a new window)';
// message to replace back links with
var closeMessage='Close window';
// links to loop over (it is a good idea to constrain this further)
var links=document.getElementsByTagName('a');
// If the window is a popup window (there is a opener window)
if(window.opener)
{
// define new regular expression to test for the rev attribute
var check = new RegExp("(^|\\s)" + backRev + "(\\s|$)");
// loop over all links
for(var i=0;i<links.length;i++)
{
// if there is no appropriate rev attribute, skip this link
if(!check.test(links[i].getAttribute('rev'))){continue;}
// if the closing message is not empty,
//replace the link text with it
if(closeMessage!=''){links[i].firstChild.nodeValue=closeMessage;}
// close the window when the link is activated
addEvent(links[i],'click',dealwithwin); }
// if the window is not a popup
} else {
// loop over all links
for(var i=0;i<links.length;i++)
{
// if the link has no appropriate rel or target attribute, skip it
if(links[i].getAttribute('rel')!=triggerRel &&
links[i].getAttribute('target')!=triggerTarget)
{continue;}
// if the link has no target, add the open message
if(!links[i].target)
{
links[i].appendChild(document.createTextNode(openMessage));
}
// open a new window with the defined attributes when the
// link gets activated and set the focus to the window.
addEvent(links[i],'click',dealwithwin);
}
}
}
}
function dealwithwin(e)
{
// define name and attributes of the popup window
var popupname='popup';
var windowAttributes='width=400,height=400,scrollbars=yes,resizable=yes,menubar=yes';
// if this function was not called in a popup window,
// try to open a window
if(!window.opener)
{
var popup=window.open(this.href,popupname,windowAttributes);
// if the popup was sucessfully opened,
// set the focus to it and don't follow the initial link
if(popup)
{
popup.focus();
// do not follow the link and open the document,
// in the same window
if(e.returnValue){e.returnValue = false;}
if(e.preventDefault){e.preventDefault();}
return false;
}
// otherwise, close this window
} else {
window.close();
}
}
function addEvent(elm, evType, fn, useCapture)
// cross-browser event handling for IE5+, NS6+ and Mozilla/Gecko
// By Scott Andrew
{
if (elm.addEventListener) {
elm.addEventListener(evType, fn, useCapture);
return true;
} else if (elm.attachEvent) {
var r = elm.attachEvent('on' + evType, fn);
return r;
} else {
elm['on' + evType] = fn;
}
}
addEvent(window,'load',popuptools,false);If you add these functions to both the opening document and the one being opened in the pop-up, the links are automatically converted. First, add them to the document triggering the pop-up window:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html dir="ltr" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<title>Pop-up Window Examples - Parent page</title>
<style type="text/css"></style>
<script type="text/javascript" src="popuptoolbox.js"></script>
</head>
<body>
<p><a href="popup.html" rel="popup">Help</a></p>
</body>
</html>And then add them to the document opened in the pop-up window:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html dir="ltr" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<title>Popup window example</title>
<style type="text/css"></style>
<script type="text/javascript" src="popuptoolbox.js"></script>
</head>
<body>
<a href="popupparent.html" rev="poptrigger">Go back</a>
<h1>This is the popup window</h1>
<p><a href="popupparent.html" rev="poptrigger">Go back</a><p>
</body>
</html>This is as accessible and unobtrusive as you can get when it comes to pop-up windows. A legitimate use might be when you need to display a third-party site or a lengthy legal text.
Another solution to this problem would be using an IFRAME and giving it a proper summary in its title. However, this is
deprecated in strict HTML 4.01 and XHTML transitional, so out of the question
if you use these.
For smaller portions of text, it might be better to use a technique called layer-ad (at least in advertising). Using this technique, you add the text to the document, hide it dynamically, and show it when the visitors interact with another element.
Showing/hiding page elements is probably one of the most common JavaScript tricks. In regards of accessibility, it can make or break the page. On the one hand, it is nice not to overwhelm the visitors with options and content, but instead offer them the choice to expand and collapse what they want. On the other hand, hiding things does not make them disappear, and users without JavaScript will need to take in all the elements at once. In a visual browser, this might not seem that taxing, but visitors who depend on a screen reader will need to listen to a lot of content that may not be of any interest to them at the moment. A classic example is a navigation menu that has all pages of the site available. For a visitor who can see and use a mouse, this might be a handy shortcut, but listening to dozens of links with no connection to the current page is not fun. A good rule of thumb is to design the page with all options available, test it with real users, and then start enhancing via JavaScript.
You can hide page elements in a variety
of ways. For example, you can setting their display property to none,
set their visibility property to hidden, or position them off the screen. Other methods involve text-indent, clip, negative
Z-indexes, hidden overflow:, margins, and line-height. A Google search for "image replacement technique" gives
you all the ideas developers have come up with from the CSS side of things.
Setting the display or visibility property can cause problems, as they could hide your content not only to the sighted visitors, but also to those using assistive technology, depending on the software used and its configuration.
One common technique to show and hide elements that works for all user agents is called off-left, as it positions the element off the screen but still keeps it readable for nonvisual user agents:
.hide{
position:absolute;
top:-9999px;
left:-9999px overflow:hidden;
}In the past, you might have encountered some code examples like this one:
<h4><a href="#address" onclick='showstuff('address')'>Our Address:</a></h4>
<address id="address" class='hide'>
<strong><a name="address">Company Name</strong><br />
House<br />
Street<br />
Post Code<br />
City<br />
County<br />
United Kingdom<br />
</address>
<p>More content</p>The problem with this example is that you
rely on JavaScript being available. Visitors with CSS enabled and JavaScript
turned off will never be able to see the address. It is much safer to add the
class and the functionality via JavaScript using the aforementioned cssjs and addEvent functions. All that remains in the HTML are two IDs to ease the
process of finding the elements to apply the functionality.
<h4 id="addresstrigger">Our Address:</h4>
<address id="address">
Company Name<br />
House<br />
Street<br />
Post Code<br />
City<br />
County<br />
United Kingdom<br />
</address>
<p>More content</p>The script itself needs to check for these two IDs and create the rest of the elements
necessary to show and hide the address.
addEvent(window,'load',initaddress,false);
function initaddress()
{
if(!document.getElementById || !document.createTextNode){return;}
var adt=document.getElementById('addresstrigger');
var add=document.getElementById('address');
if(!adt || !add){return;}
// add the link to the heading
var newa=document.createElement('a');
newa.href='#address';
var txt=adt.firstChild.nodeValue;
newa.appendChild(document.createTextNode(txt));
adt.replaceChild(newa,adt.firstChild);
addEvent(newa,'click',showhideaddress,false);
// add the named anchor to address
newa=document.createElement('a');
newa.setAttribute('name','address');
txt=add.firstChild.nodeValue;
newa.appendChild(document.createTextNode(txt));
add.replaceChild(newa,add.firstChild);
cssjs('add',add,'hide');
}The actual showing and hiding is achieved by removing or adding the hide class.
function showhideaddress()
{
var add=document.getElementById('address');
if(cssjs('check',add,'hide'))
{
cssjs('remove',add,'hide');
} else {
cssjs('add',add,'hide');
} return false;
}By using two different IDs, you take the easy way out, as you don't need to loop through elements
and try to find the ones to hide. Too much looping and checking can slow down
your scripts and should be avoided if possible. When dealing with generated
content though, you might not have the chance to create unique IDs but need to
rely on element names. For example, say you have an FAQ page you want to make
collapsible. Your code might be as follows:
<div id="faq">
<h2>Question 1</h2>
<div>
<p>Answer 1</p>
</div>
<h2>Question 2</h2>
<div>
<p>Answer 2</p>
</div>
<h2>Question 3</h2>
<div>
<p>Answer 3</p>
</div>
<h2>Question 4</h2>
<div>
<p>Answer 4</p>
</div>
</div>With the following code, you can make the question headings clickable and expand and collapse the answers.
function initfaq()
{
if(!document.getElementById || !document.createTextNode){return;}
// check if the FAQ element exists
var f=document.getElementById('faq');
if(!f){return;}
// grab all headings level two
var h2s=f.getElementsByTagName('h2');
var tohide
// loop through all the headings
for(var i=0;i<h2s.length;i++)
{
// find the next sibling element and make sure
// it is an element and a div
tohide=h2s[i].nextSibling;
while(tohide.nodeType!=1 && tohide.nodeName.toLowerCase!='div')
{
tohide=tohide.nextSibling;
}
cssjs('add',tohide,'hide');
h2s[i].tohide=tohide;
addEvent(h2s[i],'click',setElement(h2s[i]),false);
}
}
function faqcollapse(e,targetElement)
{
// find the element that was activated
var el = window.event ? targetElement : e ? e.currentTarget : null;
if (!el) return;
// check if the element stored in the tohide attribute is already
// hidden or not and hide or show it by adding or removing
// the hide class
if(cssjs('check',el.tohide,'hide'))
{
cssjs('remove',el.tohide,'hide');
} else {
cssjs('add',el.tohide,'hide');
}
}
// tool functions
function setElement(node) ...
function cssjs(a,o,c1,c2) ...
function addEvent(elm, evType, fn, useCapture) ...
addEvent(window,'load',initfaq,false);Your FAQ can now be expanded and collapsed, but there is one mistake. Using only a
keyboard to navigate the page, visitors will never be able to expand the
answers. They cannot reach and activate the headings. The remedy is to add
links around the headings and anchors inside each <div>.
function initfaq()
{
// ... code removed for legibility ...
for(var i=0;i<h2s.length;i++)
{
// find the next sibling element and make sure it is an element and a div
tohide=h2s[i].nextSibling;
while(tohide.nodeType!=1 && tohide.nodeName.toLowerCase!='div')
{
tohide=tohide.nextSibling;
}
// create a target and a link pointing to it
newtarget=document.createElement('a');
newtarget.name='faqtarget'+i;
newlink=document.createElement('a');
newlink.href='#faqtarget'+i;
// insert the target in the FAQ answer
tohide.insertBefore(newtarget,tohide.firstChild);
// read the content of the FAQ question
h2content=h2s[i].firstChild.nodeValue;
// add a link around the question
newlink.appendChild(document.createTextNode(h2content));
h2s[i].replaceChild(newlink,h2s[i].firstChild);
cssjs('add',tohide,'hide');
h2s[i].tohide=tohide;
addEvent(h2s[i],'click',setElement(h2s[i]),false);
}
}You can enhance this example to show different styles when the heading is activated and for the closed and open FAQ items by adding and removing more classes. You could also easily make the headings react when the mouse hovers over them, but that can result in unsightly jumping of the page.
Another necessary evil is that the whole
page content is visible until the page has finished
loading and the hide script has executed. There is no clean way around that
issue, but there is a hack, and it is the only justifiable use of document.write. Adding a small script that writes out the necessary hiding class
to the document ensures that when the elements get rendered, they will be
hidden. However, this fix comes with the dangers of document.write, as explained in the next section, so avoid it if possible.
Probably the biggest virtue when it comes to showing and hiding elements is restraint. It is tempting to make the whole page collapse and expand. It is a sexy feature, invites user engagement, and makes your sites look a lot more like applications. However, unless you rely a lot on JavaScript or use buttons as the interactive elements— to send the state changes to the back end for storage— you won't be able to offer the same functionality that real applications give the user. The more interactivity a page offers, the more likely users are to expect it to behave like a real application. An application stores the state of all windows, menu bars, and custom settings when you close them, and reinstates them when you open the application again. Can you be sure to offer that to your visitors safely?
When you use scripts downloaded from the Web or from older tutorials, you are likely to encounter some outdated techniques. There might be conditions where their use is still a necessity— say for to support very old browsers— but, in general, you will create much slicker and easier to maintain scripts when you stop using them and concentrate on their replacements, as described in this section.
document.writeIf you use document.write, you write out content to the HTML document, inside the body of the
document and mixed with the markup. This is not only a maintenance issue, but it can also lead to browsers
not rendering the page or visitors retrieving JavaScript code instead of the
content.
The solution is to identify the page element you want to add
content to via getElementById or getElementsByTagName, create your elements via createElement or createTextNode, and
insert them via appendChild or insertBefore. This will
also ensure that the created elements are well-formed—
something that is a
responsibility of the developer if you use document.write. If you use XHTML documents and you serve them as application/xhtml+xml on the server, document.write will not work anyway, as it is deprecated.
There is one exception, which is a
cosmetic issue: If you hide or rearrange page elements by applying classes, you
can get an unsightly shifting of the page when the document loads. Writing out
the style sheet link with document.write makes sure that the necessary classes are defined before the
changes occur, and the page load will look a lot smoother, as mentioned in the
previous section.
<noscript></noscript>The noscript directive tells the user agent what to
render when there is no scripting support enabled. You will encounter it a lot
in accessibility tutorials, where it is advertised as a way for every visitor
to use your site. What it means is that you are relying on JavaScript to be
available and trying to find a clean way out by adding a "Sorry, but you
really need JavaScript
" message. Instead of using noscript, you can leave the "no scripting" message in the document
and replace it only when scripting is available.
<p id="nojs"><strong>Warning:</strong>
You need JavaScript enabled to use this application.
If there is no way for you to enable JavaScript, please
<a href="contact.php">contact us</a> to find a way around this problem.
</p>
function replacenoscript()
{
// check if DOM is available
if(!document.getElementById || !document.createTextNode){return;}
// check if there is a "No JavaScript" message
var nojsmsg=document.getElementById('nojs');
if(!nojsmsg){return;}
// create a new paragraph and link to the application and replace
// the non-JavaScript message with it.
var newp=document.createElement('p');
var newtxt='A test of your browser configuration found no errors. ';
newp.appendChild(document.createTextNode(newtxt));
var newa=document.createElement('a');
newa.setAttribute('href','application.html');
newtxt='Proceed to the application';
newa.appendChild(document.createTextNode(newtxt));
newp.appendChild(newa);
nojsmsg.parentNode.replaceChild(newp,nojsmsg);
}This function, executed when the page
loaded, will test if there is a paragraph with the ID nojs and replace it with a message stating that the browser
configuration was successfully tested. It also creates a link pointing to the
document that needs JavaScript enabled—
in this case, application.html. You might argue that you could automatically transfer the user to
the other document via JavaScript and the window.location.href directive, but this can be prevented in modern browsers as it was
abused for unsolicited advertising and other malicious
code. Furthermore, telling the visitor that the following product must have
JavaScript enabled might make it less confusing when the product behaves
differently than a plain HTML/CGI solution.
href="javascript:..." and onclick="javascript:"There is no such thing as a JavaScript protocol
on the Web. Links use protocols like http:// or https:// to connect
documents. By using javascript: as a protocol, you make yourself dependent on scripting being
available. If you need a link that exclusively points
to a function, generate the link via the DOM and assign an event handler to it
instead.
One common use of this outdated technique is for links that point to a full-size version of an image in a pop-up window, something like this:
<p><img src="robot_tn.gif" alt="Battery powered Toy Robot" /></p>
<p><a href="javascript:showPic('robot.jpg');return false">Large Image</a></p>This link will do nothing when JavaScript is not available. Instead of using the pseudo protocol, you could link to the image with a normal link and use an event handler to call the script:
<p><img src="robot_tn.gif" alt="Battery powered Toy Robot" /></p>
<p><a href="robot.jpg" onclick=" showPic(this.href);return false">Large Image</a></p>Notice that you don't even need to repeat
the image URL twice. You just read the href attribute of the link via this.href.
If, for some reason you want to show the link only when JavaScript is available, you can use the DOM to replace a caption with a link:
<p><img src="robot_tn.gif" alt="Battery powered Toy Robot" /></p>
<p id="caption">Toy robot</p>JavaScript:
// grab the element with the ID caption
var cap=document.getElementById('caption');
// create a new link element
var newlink=document.createElement('a');
// set the link's href attribute to the large picture
newlink.setAttribute('href','robot.jpg');
// call showPic when the user clicks on the link
newlink.onclick=function(){
showPic(this.href);
return false;
}
// read the text content of the caption
var capText=cap.firstChild.nodeValue;
// set the link text to this
newlink.appendChild(document.createTextNode(capText);
// replace the text inside the caption with the link
cap.replaceChild(newlink,cap.firstChild);You might wonder why
you don't skip setting the href attribute and send the image name as a parameter to showPic directly. The reason is that the link would not be styled as a link
if it doesn't have an href,
and it is helpful for the visitor to know where the link points.
onclick="void(0)" and Other "Do Nothing"
CommandsWhy put effort into creating something that by definition is not doing anything? The only time
you will see this is when someone created a
not-too-clever script and tries to gloss over the problems it causes. If you
point a link to a JavaScript function and you don't want it to be followed once
the function has executed, end the function with a return
false.
document.all, document.layers, and navigator.userAgentUnless your project environment is
Internet Explorer 5.0 and Netscape Communicator 4.x (my condolences if it is),
there is no need for document.all, document.layers, and navigator.userAgent any longer. Object
detection is better than trying to guess what the browser in use is,
and the W3C DOM is more likely to be used in future user agents than the
earlier Netscape or Microsoft ones. If you don't know what
I am talking about or you haven't ever encountered document.layers and document.all before, just believe me that everything with document.getElementById is much more stable and future-proof than the other two.
If you use browser sniffing, by reading
the userAgent or testing for the different DOMs, you expect the user agent to
identify itself, which may not be the case. Opera, for example, identifies
itself as Internet Explorer (because the amount of websites testing for
Internet Explorer exclusively was staggering and the Opera developers didn't
want their users to be blocked out), unless the user changes that. Browser
sniffing makes you dependent on a certain user agent, and that is one of the
biggest faux pas in accessible web development.
Testing for objects, on the other hand, only means that you check if what you
apply can be understood—
much like checking the depth of the water before
jumping in head-first.
Functions with a lot of parameters like onmouseover="myCall('I','pity','the','foo',1233,'I
aint going on no plane')" are hard to
maintain, confusing, and—
if used as in this example—
add unnecessary page weight
to the document. Anything crucial to the user experience that your script needs
has to be in the document anyway, for users without JavaScript. Reusing this
markup is a lot easier, cleaner, and more maintainable than sending a lot of
parameters. If there is any reason to send parameters, a simple this (or detecting the current element via the DOM event) does the trick
in most cases, as this sends the object you clicked on to the script and you can navigate
from there.
innerHTMLCreating complex HTML constructs can be
quite a task when you use the DOM. Say you want to tell the visitors that there
is more functionality on the page than normal HTML would give them. You could
do this by adding a paragraph with the text "This document has enhanced
functionality. Read more about the enhancements and how to use them.
" and link the second sentence to a document
explaining the changes, named jshelp.html. Let's further assume that the page has a main content element that
is a DIV with the ID content. With pure DOM methods, you could do that as follows:
function addjsinfo()
{
// check if DOM is supported
if(!document.getElementById || !document.createTextNode){return;}
// define all the variables
var contentId='content';
var s1='This document has enhanced functionality. ';
var s2='Read more about the enhancements and how to use them.';
var helpurl='jshelp.html';
// if the content element exists
var con=document.getElementById(contentId);
if(!con){return;}
// create a new paragraph, and add
// the first sentence as a new text node
var helpp=document.createElement('p');
helpp.appendChild(document.createTextNode(s1));
// create a new link, point it to the help document
// and add the second sentence as a new text node
var helplink=document.createElement('a');
helplink.setAttribute('href',helpurl);
helplink.appendChild(document.createTextNode(s2));
// add the new link to the paragraph
helpp.appendChild(helplink);
// add the paragraph before the first child element of the content
con.insertBefore(helpp,con.firstChild);
}Using the nonstandard innerHTML attribute, things get a lot easier:
function addjsinfoinner()
{
if(!document.getElementById || !document.createTextNode){return;}
var con=document.getElementById('content');
if(!con){return;}
var jsmsg='<p>This document has enhanced functionality.
<a href="jshelp.html">Read more about how to use the enhancements</a>
</p>';
con.innerHTML=jsmsg+con.innerHTML;
}However, the issue with innerHTML is that you mix JavaScript and HTML syntax.
Instead of properly constructing your markup (and thereby leaving a trail of
variables that can be reused later), you define HTML as a string of text and
offer maintainers the option to create invalid HTML that might break the page
rendering.
What innerHTML is really good for is testing your scripts.
Together with the window.alert method, it allows you to see what you have
assembled in your DOM script easily (another option is the View Generated Source option of Mozilla). Depending on
the browser, and the DOCTYPE, browsers will give you invalid markup though: elements in
uppercase and attributes without quotation marks.
Forms make the Web truly interactive. Links allow visitors to go from one page to another. You can add rollover effects and drag-and-drop functionality. But only forms allow the visitor to enter text, send it off to the server, and see what happens with it. (It is possible to create a drag-and-drop interface that also sends information to the server via Ajax, but that is hardly accessible.) Filling out a long form can be quite an annoying experience though, especially when it has been badly designed or enhanced via JavaScript without testing it first.
By now, many people have realized that you can jump from form element to form element by hitting the Tab key, thus making the data-entry process a lot quicker. You don't have to point your mouse to the text field and activate it; you simply press Tab once and start typing. Depending on the data you need to enter, you might not even look at the screen. Instead, you might look at a paper document to find a reference number, the address to transfer a payment to, and how much you have to pay. This process becomes all the more frustrating when you realize after entering the third number that the form is still stuck in the first text field, and a JavaScript alert with all the charm and grace of a charging rhino is displayed on the screen to tell you that something is wrong, as shown in Figure 10-4.
Figure 10-4. How not to tell the user that something went wrong. A javascript alert reads your reference number must be 6 digits long!
Forms are the enfants terrible of web page elements. They refuse to be styled consistently or at all, they can be a good entry point for hackers if they are not developed securely, and they are annoying to fill out. If you have many forms on your web product, make sure to assign a lot of usability testing time to those.
The better you plan the forms, the easier it will be for the end users to fill in those forms. Does every element have a proper label? Is it clear what syntax is required for the data? Did you choose the right form element for the job (why have two radio buttons stating yes and no when one check box does the same thing)?
When developing for the Web these days, forms feel cumbersome and dated. Faster computers, slicker and richer operating systems, and application interfaces make the old HTML/server interaction appear too slow and annoying to use. This has become especially obvious in the past year or so, when more and more applications installed on the operating system started talking to the Web. These fat client applications follow different rules than websites and offer a richer interface with more widgets than HTML offers, such as sliders, calendars, combo boxes, and contextual menus. All of these come with keyboard shortcuts, and many are customizable to the user's needs. The problem with web applications and websites is that they are already running inside at least two different applications— the operating system and the browser— both of which take up a lot of the available keyboard shortcuts.
As a JavaScript developer, you can enhance web applications written in HTML enormously. However, while it is possible to simulate rich client applications with JavaScript and HTML, it is not necessarily a good idea, especially when you want to stay accessible to all users.
As JavaScript developers, we love the power this language gives us, and it is very tempting to reinvent the wheel or enhance anything we see to function better than the boring old HTML controls. This is not necessarily bad, but it can be dangerous. A lot of usability testing and research has gone into the out-of-the-box HTML controls, and once web surfers have become used to them, they do not have to think twice when confronted with them again.
However, there are some things that are too good to be left out for the sake of accessibility and usability. One of them is the date picker. Date fields in forms can be a really frustrating experience, both for the visitor and for the site maintainer. There are simply too many conventions on how to enter a valid date, and they vary from country to country. The worst solution is to offer select boxes for day, month, and year, for the simple reason that not every month has 31 days. You can change the available options of the day drop-down list dynamically via JavaScript, but you cannot assume that a blind visitor will be notified about that change. The most accessible way is a free text-entry field with a sample value and an explanation in the label.
A very high-end solution to the date field problem is a date picker or a pop-up calendar. There are many scripts available, and the newer ones offer clean code and easy style changes. However, none of these are really accessible, as they are a pain to use via keyboard, voice recognition, or screen reader. This does not mean that you should not use them— they do enhance form usability greatly. Rather, it means that they should be applied only when JavaScript is available, and the form should be editable regardless of their function.
This applies to any form enhancement. If you want to offer interacting select boxes to allow for sorting two lists, you can do so; however, make sure that all the buttons and fields that require JavaScript are also created via JavaScript. Sometimes, the fallback server-side also needs to become a different interface— one that offers easier selection when pages must be reloaded. With interacting select boxes, this might be a list of check boxes.
For some web applications, the form controls HTML provides out of the box might not be enough, and the functional specifications ask for richer controls like sliders and Microsoft Excel-like spreadsheets. A lot of development frameworks like Microsoft's .NET have these, but the accessibility of them is rather poor in most of the cases. Instead of trying to roll your own solutions and bearing the whole testing and development on yourself, it might be a good idea to take a leaf out of the book of Mozilla, who has worked together with Sun on a set of rich controls that are keyboard accessible and released under the creative commons license. You can find the current releases and documentation at www.mozilla.org/access/dhtml/.
You can do a lot of validation and form enhancement via JavaScript and also automatically change values when the user goes to the next field, but you cannot rely solely on JavaScript; you need to back it up with a server-side script. This means double maintenance of validation rules: once in the JavaScript and a second time in the server-side script. Any change to the rules means that both scripts need to be updated. On top of that, you also need to tell the user explicitly what data is expected in the form label or initial value.
This does not mean that you shouldn't do any JavaScript validation— far from it. A reload spared is a good thing for both your visitors and your server traffic. Rather, it means that your validation should follow some rules:
onblur/onfocus instead of onmouseover/onmouseout).The cleanest way to validate a form is to do so when it is submitted, instead of validating every element and giving immediate feedback. Nothing is more annoying than a form that keeps changing while you use it, even if that change was meant to prevent the visitor from making errors. After submitting the form, you can create a list of elements that have erroneous data and provide links pointing to the respective field. That way, keyboard, mouse, and screen reader users can spot and reach the fields that need amending. This less dynamic way of validation also spares you assigning event handlers to each element, which might be a slow and memory-intense process, depending on the complexity of your form.
There are several ways to identify a form element that is mandatory or needs validation. You can have a
list of mandatory element names in a hidden field, you can add a special CSS
class to the fields that need to be validated, or you can just have a
JavaScript array with all the field names. All options have the "double
maintenance" issue.
Clever scripts maintain the validation rules in a shared back-end script that, depending on how it is triggered, writes out the necessary JavaScript or just validates what has been sent to the server. Examples of these are the PHP Pear package HTM_QuickForm or Manuel Lemos's formsgeneration class.
As you should tell the user, regardless of technology, which form field is a mandatory one, you could also reuse this information to tell your script which fields need its attention. You do rely on proper HTML in this case, but it seems to be the cleanest solution of them all. Let's say you have a name field. A common way to indicate that it is a mandatory field is to add an asterisk after the field and explain before the form starts that asterisks indicate a mandatory field.
<p>
<label for="name">Your Name:</label>
<input type="text" id="name" name="name" size="20" />
<span class="mandatory">*</span>
</p>Your validation script could now check
all input, textarea, and select elements inside the form and test if their next sibling is a span with the CSS class mandatory. Then it could validate the field, checking for a value or the checked attribute, respectively, depending on
whether the field is a text field or check box/radio button. Further validation
rules could be applied depending on the field's ID.
If you want to use this functionality,
make sure to keep a note of that in your web product's maintenance documents;
otherwise, a web designer might change the location of the span and prevent your script from validating.
This chapter can only be a teaser of what JavaScript and the DOM have to offer and how it can clash with accessibility. Even the code examples here will change, and it is a good idea to revisit the book's homepage from time to time.
The following are some good JavaScript resources: